Apache Airflow 2.2: практический курс: New York Yellow Taxi Data Pipeline / Описание и структура
Датасет, содержащий поездки на такси по городу Нью-Йорк, пожалуй, один из самых распространённых примеров анализа данных. Данные открыто лежат на сайте.
Задача пайплайна — скачать сырые данные с сайта, трансформировать их в колоночный формат Parquet и загрузить в S3. Это одна из типичных задач дата инженеров, когда необходимо что-то откуда то выгрузить, сохранить и трансформировать.
В качестве хранилища я буду использовать AWS S3. Это популярный сервис для хранения файлов от компании Amazon, также S3 можно рассматривать как распределенную файловую систему. Чтобы воспользоваться AWS S3 необходимо иметь аккаунт в облаке AWS, также хранение данных на S3 предполагает некоторые расходы. Для тех, кто не хочет платить, я приведу альтернативу, которую можно развернуть у себя на компьютере. Сервис Minio полностью совместимый с S3 файловый сервер, поэтому Apache Airflow будет работать с ним как с AWS S3.
Пайплайн (DAG) будет состоять из следующих операторов:
Вот как выглядит это на диаграмме с зависимостями:
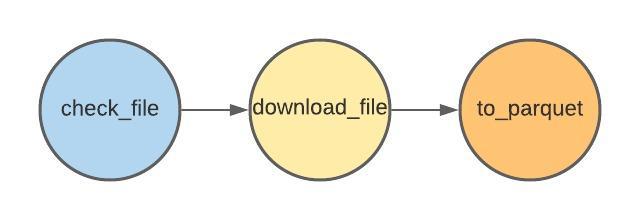
Безусловно выполнение последующего шага зависит от успешности предыдущего. Если необходимого файла на сервере нет (check_file), то выполнение загрузки нецелесообразно (download_file), за этим строго следит Airflow.